Research:
My research interest lies at the intersection of statistical machine learning, mathematics, computer vision, signal and speech processing. Below is a short summary of some of my research projects.
Information Pursuit (IP) for Sequential Scene Interpretation:
Scene interpretation is effortless and instantaneous for human beings. However, scene understanding (including object recognition) is perhaps the most challenging task in computer vision. The dream is to build a “description machine” which produces a rich semantic description of the underlying scene, including the names and poses of the objects that are present, even “recognizing” other things, such as actions, context, and the 3D layout of scenes. None of the mathematical frameworks clearly points the way to closing the gap with natural vision. Deep convolutional neural networks (CNNs) have received a flurry of interest in the past few years due to their superior performance. However, deep networks are computationally expensive and without efficient implementation on high performance computing systems not as practical as older methods. Furthermore, CNNs do not benefit from the human's visual selective attention and top-down contextual feedback connections. The human visual system makes extensive use of contextual information to facilitate and refine object detection. Object detection and recognition based only on intrinsic features of target objects is not usually sufficient for reliable inference. In this project, we used a model-based approach to incorporate top-down contextual information, and analyze scenes in a coarse-to-fine fashion inspired by the visual selective attention property of humans.
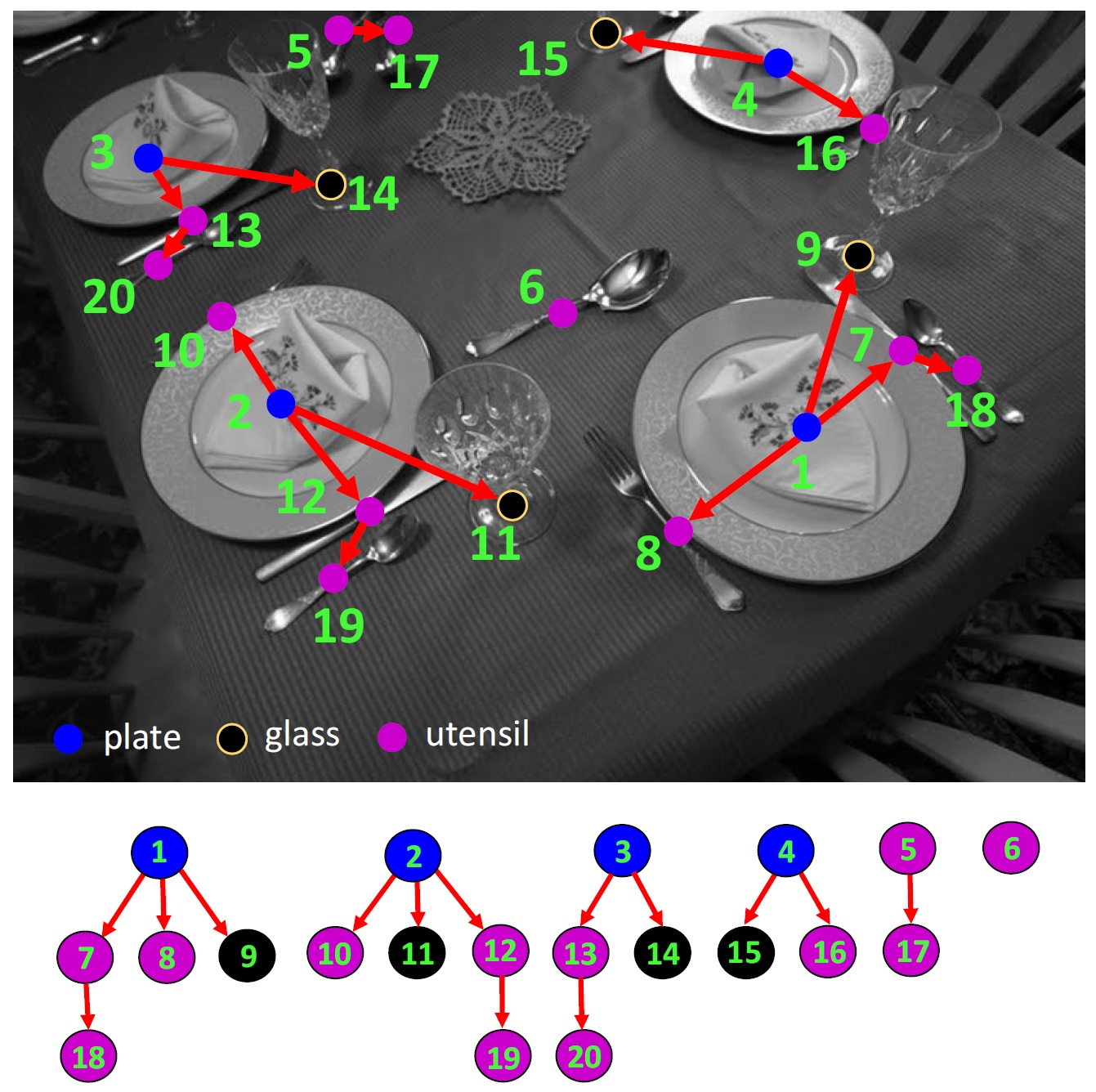
In addition to disambiguating object detection, the space of objects and their poses can be searched more efficiently by taking advantage of the contextual relations between different scene entities. We presented a new approach to efficiently search the space of objects and their poses using a Bayesian method called ‘‘Information Pursuit’’, where contextual relations between object instances and other scene entities are incorporated via a prior model. Using the entropy pursuit approach we collect bits of information about the scene sequentially by greedily selecting patches whose analysis provide the most information in an information-theoretic sense. As proof of concept we used the entropy pursuit method for multi-category object recognition in table-setting scenes (see JHU-Table_Setting Dataset). With the new wave of “Internet of Things” (IoT), smart kitchens are not far from reality (e.g., see the IKEA smart kitchen concept for 2025).
Efficient search and evidence integration appear indispensable for understanding cluttered and complex scenes with many object instances (e.g., a kitchen). Our approach is inspired by two facets of human search: the divide-and-conquer search strategy (often used by parlor game players e.g., in the “Twenty Questions” game) and the selective visual attention in natural vision. In particular, we wanted to design algorithms for shifting focus from one location to another with a fixed spatial scope, and for rapid and adaptive zooming, allowing one to switch from monitoring the scene as a whole to local scrutiny for fine discrimination, and back again depending on current input and changes in target probabilities as events unfold. There is evidence to support sequential analysis of scenes in brain with ability to shift attention rapidly from one location to another that may appear seamless (see Buschman and Miller); Therefore: “Think You’re Multitasking? Think Again”. The part of brain that is in charge of shifting attention is called ‘‘executive system’’ located in the frontal lope. The executive system helps us achieve a goal by prioritizing information and dampening down distractions. We are basically sipping at the outside world through a straw of limited consciousness. The human mind is very curious and wants to take in maximize information through this limited bandwidth. We update and make prediction based on the most recent evidence collected – in a way similar to an adaptive Bayesian approach.
Our “Information Pursuit” approach for multi-category object recognition sequentially investigates patches from an input test image in order to come up with an accurate description by processing as few patches as possible. Our approach follows the Bayesian framework with a prior model that incorporates the contextual relations between different scene entities such as the spatial and semantic relations among object instances, consistency of scales, constraints imposed by coplanarity of objects, etc. We designed a novel generative model on attributed graphs with flexible structure where each node in the graph corresponds to an object instance attributed by its category label and 3D pose (see Figure below). The GAG model was not directly used in our IP framework, but the statistics calculated from its samples were used to learn a Markov Random Field (MRF) model employed directly by IP. Whereas, the GAG model could be learned efficiently from the limited number of annotated images, the MRF model offered faster conditional inference. The Information Pursuit search strategy selects patches from the input image sequentially and investigates them to collect evidence about the scene. To investigate each patch we utilized state-of-the-art convolutional neural networks (CNNs). We used the JHU-Table_Setting Dataset to learn the Generative Attributed Graph (GAG) model, to train a battery of CNN classifiers, and to test the performance of the IP algorithm. The Bayesian framework is the natural approach for integrating contextual relations and the evidence collected using tests. We investigated the possibility of generating a scene interpretation by processing only a fraction of patches from an input image. Our results confirmed the hypothesis that we can identify an accurate interpretation by processing only a fraction of patches if the right patches are selected in the right order. We may also save computation time by processing only a fraction of patches.
 |
Please refer to the following references for more details:
E. Jahangiri, E. Yoruk, R. Vidal, L. Younes, D. Geman, “Information Pursuit: A Bayesian Framework for Sequential Scene Parsing”, Jan 2017 [arXiv:1701.02343, pdf].
E. Jahangiri, R. Vidal, L. Younes, D. Geman, “Object-Level Generative Models for 3D Scene Understanding”, CVPR Scene Understanding Workshop (SUNw), June 2015, Boston [pdf, poster].
Here are my slides for an invited talk that I gave recently.
My PhD advisor Prof. Donald Geman gave a plenary talk about this work at SIAM 2016 Conference on Imaging Science. This is the video and this is his slides. He also gave a talk for the 60th anniversary of the Department of Statistics at the University of Chicago. Here is the announcement for the Bahadur Memorial Lectures. I also gave an invited talk at the Mid-Atlantic Computer Vision (MACV) Workshop in May 2016.
Human Pose Estimation:
Estimating the 3D pose configurations of complex articulated objects such as humans from monocular RGB images is a challenging problem. There are multiple factors contributing to the difficulty of this critical problem in computer vision: (1) multiple 3D poses can have similar 2D projections. This renders 3D human pose reconstruction from its projected 2D joints an ill-posed problem; (2) the human motion and pose space is highly nonlinear which makes pose modeling difficult; (3) detecting precise location of 2D joints is challenging due to the variation in pose and appearance, occlusion including both from other people (or objects) and self-occlusion, and cluttered background. Also, minor errors in the detection of 2D joints can have a large effect on the reconstructed 3D pose. These factors favor a 3D pose estimation system that takes into account the uncertainties and suggests multiple possible 3D poses. Often in the image, there exist much more detailed information about the 3D pose of a human (such as contextual information and difference in shading and texture due to depth disparity) than the 2D location of the joints. Hence, most of the possible 3D poses consistent with the 2D joint locations can be rejected based on more detailed image information (e.g., in an analysis-by-synthesis framework) or by physical laws (e.g., gravity). However, note that the image may not contain enough information to rule out or favor one 3D pose configuration over another especially in the presence of occlusion and therefore there exists a level of uncertainty in such cases. In this project, we focus on generating multiple plausible 3D pose hypotheses which while satisfying humans anatomical constraints, including the joint angle limits and limb length ratios, are still consistent with the output of the 2D joint detector. Figure below illustrates an overview of our approach.
 |
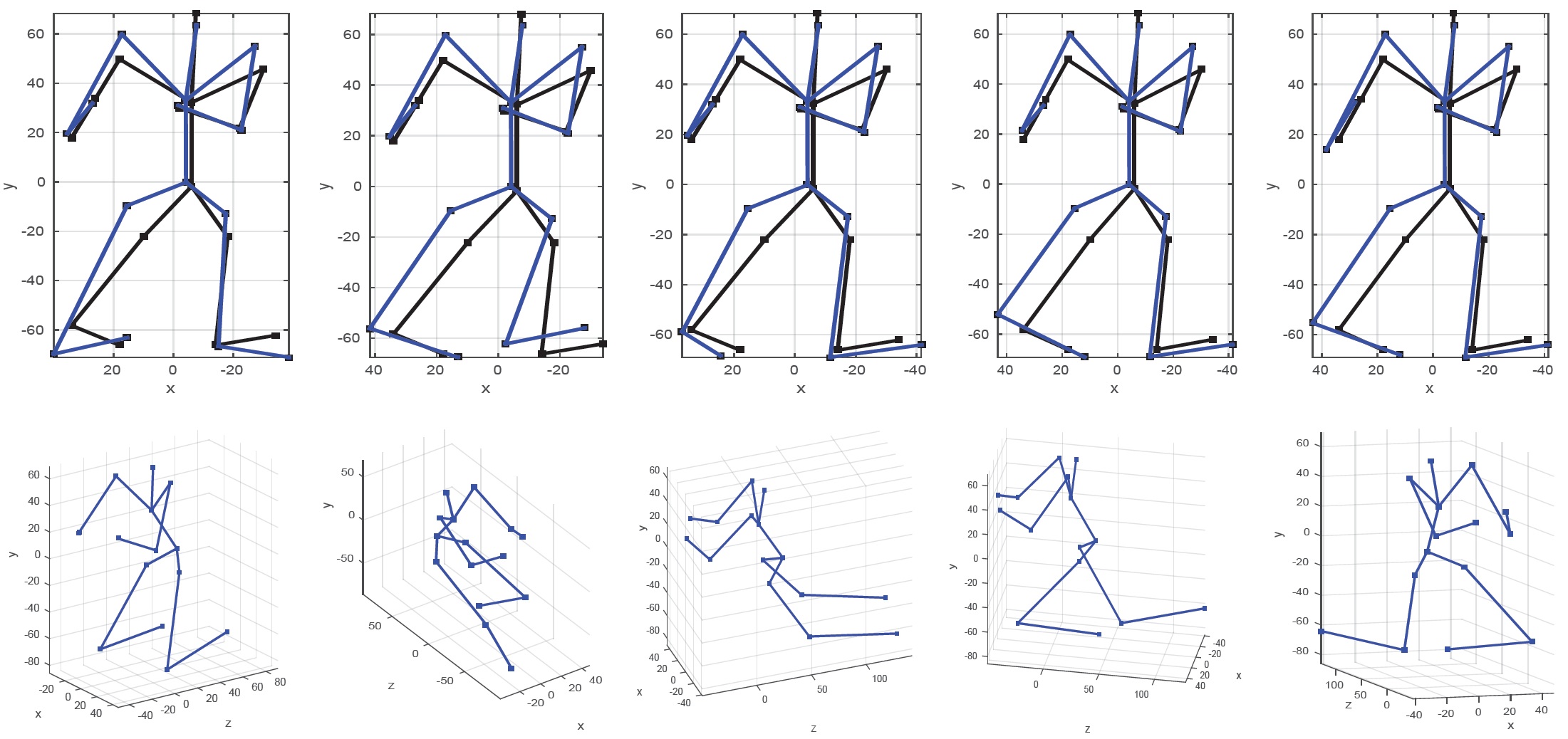
The below figure shows the generation of five diverse 3D pose hypotheses consistent with the 2D joint detections output by ‘‘Stacked Hourglass’’. The first row shows the 2D detections (black skeleton) and the projection of 3D pose hypotheses (blue skeleton). The corresponding 3D pose hypotheses are shown on the second row right below their 2D projections from a different viewpoint. It can be seen that the generated 3D pose hypotheses are quite different even though their projections are similar and consistent with the 2D detections.
 |
Reference:
E. Jahangiri, A.L. Yuille, “Generating Multiple Diverse Hypotheses for Human 3D Pose Consistent with 2D Joint Detections”, ICCV 2017, Venice, Italy (PeopleCap Workshop). [pdf].
Stochastic Optimization:
Stochastic Approximation (SA) algorithms have seen a flurry of interest recently with the dawn of big data and deep learning. An important version of the SA algorithms is the averaged stochastic gradient descent (ASGD) which has an asymptotically optimal convergence rate. Smoothness of the ASGD iterates makes it attractive in cases where the measurements have large variance. However, to ensure convergence, the bulk of iterates should fall uniformly within a relatively tight proximity of the solution. Convergence of the averaged sequence can be sluggish if the iterates do not reach this point relatively quickly. Furthermore, note that this convergence issue is even more pronounced in robust stochastic approximation (RSA) where the converging sequence is a weighted average of the SGD iterates with decreasing weights. The decreasing weights lower the significance of later iterates which are more likely to fall within a close proximity of the solution compared to the initial iterates. Therefore, an acceleration of convergence, even in the early iterates, can substantially benefit RSA. In this project, I proposed an accelerating and adaptive step-size based on the evidence collected from the most recent iterates via an oscillation measure that can speed up convergence in early iterations. This accelerating step-size adds only negligible computational burden which makes is particularly attractive for large-scale problems. The proposed step-size showed considerable accelerated convergence in experiments. I proved convergence of ARSA.
Reference:
E. Jahangiri, “Accelerated Robust Stochastic Approximation”, (coming soon).
Speech Coding:
In this project, I worked on a scalable speech coding scheme using the embedded matrix quantization of the line spectral frequencies (LSFs) in the LPC model. For an efficient quantization of the spectral parameters, two types of codebooks of different sizes are designed and used to encode unvoiced and mixed voicing segments separately. The tree-like structured codebooks of our embedded quantizer, constructed through a cell merging process, help to make a fine-grain scalable speech coder (< 900bps). Using an efficient adaptive dual-band approximation of the LPC excitation, where voicing transition frequency is determined based on the concept of instantaneous frequency in the frequency domain, near natural sounding synthesized speech is achieved. Assessment results, including both overall quality and intelligibility scores show that the proposed coding scheme can be a reasonable choice for speech coding in low bandwidth communication applications.
References:
E. Jahangiri, and S. Ghaemmaghami, “Very Low Rate Scalable Speech Coding Through Classified Embedded Matrix Quantization”, EURASIP Journal on Advances in Signal Processing Volume 2010 (2010), Article ID 480345 [link, pdf].
E. Jahangiri, and S. Ghaemmaghami, “Scalable Speech Coding at Rates Below 900bps”, 2008 IEEE International Conference on Multimedia and Expo (ICME’08), Hannover, Germany, pp.85-88, June 23-26 2008 [link, pdf].
Data Hiding in Multimedia Signals:
In this project, I worked on a new approach to data hiding that leads to a high data embedding rate of tens of kbps in a typical digital voice file transmission scheme. The purpose of the proposed method is restricted to offline voice transmission that uses stego speech files in wave format. The basic idea of the algorithm is to embed encrypted covert message in the unvoiced bands of spectrum of the cover speech. Inaudibility of the proposed hiding scheme was investigated through both support vector machines (SVM)-based steganalysis and the ITU-T P.862 PESQ standard speech quality assessment. The results assured imperceptibility and transparency of the stego speech. I also helped in developing new and efficient steganalysis methods in order to detect hidden messages in image, video, and audio signals.
References:
E. Jahangiri, and S. Ghaemmaghami, “High rate data hiding in speech using voicing diversity in an adaptive MBE scheme”, 2008 IEEE TENCON Conference (TENCON’08), Hyderabad, India [link, pdf].
E. Jahangiri, and S. Ghaemmaghami, “High Rate Data Hiding in Speech Signal”, International Conference on Signal Processing and Multimedia Applications (ICETE/SIGMAP’07), Barcelona, Spain, 28-31 Jul 2007 [pdf].